






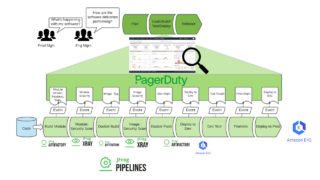




結論としてはAgentはアーキとしてないと辛いし、詰む可能性が非常に高い。
Agentあり
結論から申し上げますと、はい、Bedrockは数値を出力する業務に非常に向いています。ただし、それはBedrockに「計算」をさせるのではなく、Bedrockを「司令塔」として使う場合です。
文章を一切扱わない、というご認識ですが、実はLLM(大規模言語モデル)を動かす上では、入力(指示)も出力(数値)も、その背景や意味づけは言語情報として扱われます。この点を踏まえて、2つのアプローチを比較することで、Bedrockの正しい使い方をご理解いただけます。
アプローチ1:間違った使い方(Bedrockに直接計算させる)
これは、Bedrockの基盤モデル(LLM)に対して、計算問題そのものを解かせるアプローチです。
例:
プロンプト:
「12345 * 67890 を計算してください。」
この使い方は全く推奨されません。
なぜ向いていないのか?
- 信頼性の欠如: LLMは計算機(Calculator)ではなく、確率的に「それらしい」次の単語(トークン)を予測する言語生成モデルです。そのため、特に複雑な計算や桁数の多い計算では、平気で間違った数値を「もっともらしい回答」として生成します(これをハルシネーションと言います)。
- 精度の問題: 金融計算のような小数点以下の精度が求められる業務では、致命的な誤差を生む可能性があります。
- 再現性の欠如: 同じ質問をしても、モデルのパラメータによっては毎回違う答えが返ってくる可能性があります。ビジネスの数値においてこれは許容されません。
一言でいうと、LLMは数学者ではなく、非常に物知りな文系アシスタントです。彼に暗算をさせるのは間違いです。
アプローチ2:正しい使い方(Bedrockを司令塔として使う)
こちらが、Bedrockを数値処理業務に活用するための本来の使い方です。Bedrock(特に Agents for Amazon Bedrock)を、ユーザーからの自然言語の指示を理解する「賢い頭脳」として位置づけ、実際の数値処理はそれに特化した専門のツールに任せます。
構成図:
[ユーザー]
「先月の関東エリアにおける商品Aの売上合計は?」 (自然言語での指示)
↓
[Agent (Bedrock)]
(指示を解釈し、「どのツールで何をするべきか」を判断)
│
└─ 指示:「商品Aの売上合計を関東エリアで集計せよ」
↓
[ツール (AWS Lambdaなど)]
(Agentからの指示に基づき、専門的な処理を実行)
│
├─ 1. データベース(PostgreSQL)に接続
├─ 2. 以下のSQLを実行
│ SELECT SUM(uriage) FROM sales_table WHERE area = 'kanto' AND product_id = 'A';
└─ 3. 結果の数値「15,234,500」を取得
↓
[Agent (Bedrock)]
(ツールから返ってきた数値「15,234,500」を受け取る)
↓
[ユーザー]
(結果を整形して提示)
「15,234,500円です。」
なぜこちらが向いているのか?
- 絶対的な信頼性: 実際の計算やデータ集計は、データベースやプログラム(Pythonなど)といった、その処理のために設計された正確無比なツールが行います。結果は100%正確です。
- 専門性の活用:
- データ集計・検索: データベース (SQL)
- 統計分析・科学技術計算: Pythonライブラリ (Pandas, NumPy) をLambdaで実行
- BIツール連携: QuickSightなどのAPI呼び出し
- ERP/基幹システム連携: 各システムのAPI呼び出しBedrockはこれらの専門家たちに的確に指示を出すマネージャーの役割を果たします。
- 自然言語インターフェースの実現: 最大のメリットです。経理担当者や経営層が、SQLを知らなくても「先月の売上は?」と聞くだけで、裏側では正確なSQLが実行され、信頼できる数値が得られます。文章を扱わない業務であっても、人間が指示を出すインターフェースは自然言語(文章)が最も効率的なのです。
Agentなし
結論から申し上げますと、「可能ですが、重大なセキュリティリスクを理解し、それを回避するための厳格な設計が必須」となります。専門家としては、特定の方式を強く推奨し、別の方式は原則として避けるべきだと考えます。
Agentを使わない場合、アプリケーションが直接Bedrockの基盤モデル(LLM)と対話することになります。その際、考えられるアプローチは2つあります。
アプローチ3:パラメータ抽出モデル(推奨される唯一の方法)
この方法では、BedrockのLLMにSQL文そのものを生成させるのではなく、ユーザーの自然言語の指示からSQLの条件句に必要な「パラメータ(値)」だけを抽出させます。実際のSQL文は、アプリケーション側にあらかじめ用意しておいた安全なテンプレートを使用します。
処理フロー:
[ユーザー]
「ステータスが有効で、東京都在住の利用者の人数を教えて」
↓
[1. アプリケーション]
(ユーザーの指示をBedrockに送信)
↓
[2. Bedrock 基盤モデル (LLM)]
(指示を解釈し、SQLのパラメータだけを構造化データ(JSON)で抽出)
↓
出力 -> { "status": "有効", "address": "東京都" }
↓
[3. アプリケーション]
(抽出されたJSONを受け取る)
- あらかじめ用意しておいたSQLテンプレートを選択:
"SELECT COUNT(*) FROM users WHERE status = ? AND address LIKE ?;"
- 抽出された値を、SQLインジェクションが起こらないように安全な方法(プレースホルダ)でバインド
↓
[4. データベース]
(安全に構築されたSQLを実行し、結果の数値を返す)
↓
[5. アプリケーション]
(結果をユーザーに提示)メリット
- セキュリティが極めて高い: 実行されるSQLの骨格はテンプレートで固定されているため、LLMを悪用したSQLインジェクションを完全に防げます。
- 信頼性とパフォーマンス: テンプレートのSQLは事前に最適化・テストされているため、常に高速で正確な結果が保証されます。
- 制御が容易: どのようなSQLが実行されるかが明確であるため、システムの振る舞いを完全に管理下に置けます。
デメリット
- 柔軟性の制約: あらかじめテンプレートとして用意されたSQLのパターンしか実行できません。
アプローチ4:直接SQL生成モデル(非推奨・極めて高リスク)
この方法では、BedrockのLLMに、ユーザーの指示に基づいてSQL文そのものを自由に生成させ、その文字列をそのままデータベースで実行します。
処理フロー:
[ユーザー]
「ステータスが有効で、東京都在住の利用者の人数を教えて」
↓
[1. アプリケーション]
(指示とDBのスキーマ情報をプロンプトとしてBedrockに送信)
↓
[2. Bedrock 基盤モデル (LLM)]
(SQL文の文字列を生成)
↓
出力 -> "SELECT COUNT(*) FROM users WHERE status = '有効' AND address LIKE '東京都%';"
↓
[3. アプリケーション]
(生成されたSQL文字列をそのまま実行) <-- !!! 重大なセキュリティリスク !!!
↓
[4. データベース]
(受け取ったSQLを実行)このアプローチの致命的なリスク
- SQLインジェクション: 最大のリスクです。 悪意のあるユーザーが「”hoge”; DROP TABLE users;–」のような巧妙な指示を入力することで、LLMにデータベースを破壊するSQLを生成させ、実行させてしまう可能性があります。
- 不正確なクエリ: LLMがスキーマや指示を誤解し、間違った条件でデータを取得・集計してしまう(サイレントエラー)危険性があります。
- パフォーマンス問題: LLMが生成するSQLはインデックスを考慮しない非効率なものが多く、データベースに過大な負荷をかける可能性があります。
- 情報漏洩: 想定外のテーブルをJOINしたり、WHERE句が欠落したりすることで、ユーザーの権限を越えたデータが漏洩するリスクがあります。
結論と推奨
「Agentを使用せず、文章も扱わない」という条件でのSQL実行業務において、
- アプローチ3(パラメータ抽出モデル)は、セキュリティと信頼性を担保できる唯一現実的で推奨される方法です。Bedrockを「超高性能な自然言語理解エンジン」として活用する、非常に賢い使い方と言えます。
- アプローチ4(直接SQL生成モデル)は、セキュリティリスクが極めて高いため、本番環境での利用は絶対に避けるべきです。 外部に非公開の、ごく一部の開発者が利用する管理ツールや、使い捨てのプロトタイプといった特殊な状況以外での採用は考えられません。
ご提示の業務は、アプローチ1を採用することで、安全かつ効率的に実現することが可能です。

コメント