
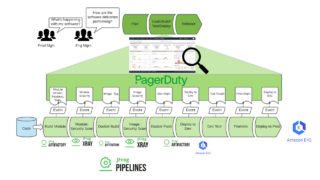









OpenSearchのVector DBを効果的に使うには、ベクトルのインデックス名、次元数、距離メトリクス、検索アルゴリズムを定義することが重要です。運用では、企業独自の非構造化データをチャンク化し、埋め込みモデルでベクトル化して格納します。これにより、ハイブリッド検索が可能になり、RAGソリューションで正確なAI応答が実現します。
効果的な定義
BedrockのKnowledge Baseと連携してOpenSearchのVector DBを使用する場合、主に以下の点を定義することが重要です。
- ベクトルインデックス名とベクトルフィールド名:
- ベクトルデータを格納するためのインデックス名と、そのベクトルを格納するフィールド名を定義します。
- BedrockのKnowledge Baseを使用する場合、
AMAZON_BEDROCK_TEXTやAMAZON_BEDROCK_METADATAのような特定のフィールド名が使用されることがあります。
- 次元数(Dimension):
- 使用するBedrockの埋め込みモデル(Embedding Model)に合わせて、ベクトルの次元数を設定します。例えば、
Titan Text Embeddings v2モデルを使用する場合は、1024、512、または256のいずれかの次元数が必要です。
- 使用するBedrockの埋め込みモデル(Embedding Model)に合わせて、ベクトルの次元数を設定します。例えば、
- 距離メトリクス(Distance Metric):
- ベクトル間の類似度を計算するためのアルゴリズムを選択します。ユークリッド距離やコサイン類似度などが一般的です。
- エンジン/アルゴリズム:
- ベクトル検索の性能を最適化するために、使用する検索アルゴリズム(例:HNSW、IVFなど)を選択します。OpenSearchは、FAISS、NMSLIB、Luceneなどのエンジンをサポートしています。
- ハイブリッド検索:
- キーワード検索とベクトル検索を組み合わせて、検索結果の関連性を高めるハイブリッド検索機能を活用することが効果的です。
投入可能でデータ
OpenSearchのVector DBに投入すべきデータは、主に以下のものが挙げられます。
- 非構造化データ:
- PDF、ドキュメント、メール、チャットログ、ウェブサイトのコンテンツなど、企業独自の非構造化データ。
- これらのデータは、まず「チャンク化」と呼ばれるプロセスで、扱いやすい小さなテキスト片に分割されます。
- 埋め込み(Embedding):
- 分割されたテキストのチャンクを、Bedrockの埋め込みモデルを使用してベクトル(数値の密な配列)に変換します。
- このベクトルが、OpenSearchのVector DBに格納される主要なデータとなります。
- メタデータ:
- 元のドキュメントのタイトル、作成者、作成日、ドキュメントのソースURLなど、ベクトル化されたデータに関連する情報。
- これにより、検索時に特定の条件でフィルタリングしたり、検索結果にコンテキストを追加したりすることが可能になります。
- 複数のデータソース:
- OpenSearchは、Amazon S3、Confluence、Microsoft SharePoint、Salesforce、Webクローラーなど、さまざまなデータソースと連携してデータを取り込むことができます。
これらの要素を適切に定義し、運用することで、BedrockとOpenSearchを組み合わせたRAG(Retrieval Augmented Generation)ソリューションを構築し、コンテキストに応じた正確な応答を生成するAIアプリケーションを実現できます。
検索機能の強化に役立つベクトルデータベース駆動型検索機能については、こちらの動画をご覧ください: Enhance search with vector database-driven search capabilities


コメント