



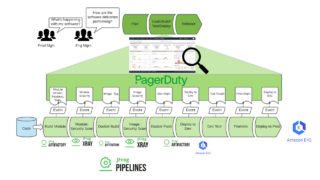





Amazon Bedrock のバックエンドで PostgreSQL(特に Aurora PostgreSQL)を使用する場合、パラメータチューニングは有効です。適切なチューニングにより、ベクトル検索のレイテンシ削減、RAG(Retrieval-Augmented Generation)の効率化、リソース枯渇の回避が可能になります。以下に、有効性の根拠と具体的なチューニングポイントを整理します。
パラメータチューニングが有効な理由
- ベクトル検索の高速化:
Bedrock の RAG では、Aurora PostgreSQL に保存されたベクトルデータに対する近傍検索(例:vector_cosine_ops)が頻発します。インデックス構築パラメータやメモリ設定の最適化で検索速度が向上します。 - リソース競合の緩和:
並列クエリや接続集中時のメモリ/CPU 使用率を制御し、Bedrock Agent や RAG のレスポンス遅延を防げます。 - コスト効率性:
適切なチューニングでインスタンス規模の縮小やスループット向上が可能となり、運用コストを削減できます。
チューニングの核心ポイント
1. メモリ関連パラメータ
work_mem:
ソートやハッシュ結合用のメモリ量。ベクトル検索時の一時ファイル生成を抑制するため、デフォルト(4MB)から増加(例:32MB)が有効。過剰設定はメモリ枯渇の原因となるため注意。sql -- 推奨設定例(セッション単位) SET work_mem = '32MB';maintenance_work_mem:
HNSW インデックス再構築時のメモリ割り当て。大規模ベクトルテーブルでは 256MB 以上 に設定し、インデックス作成時間を短縮。shared_buffers:
データキャッシュ領域。Aurora はストレージ層が最適化されているため、インスタンスメモリの 25% 程度 が目安。
2. 並列処理とインデックス最適化
- 並列クエリの有効化:
max_parallel_workers_per_gatherを 8 以上 に設定し、大規模テーブルの結合を高速化。HINT句(/*+ Parallel(t 8 hard) */)で強制適用も可能。 - HNSW インデックスパラメータ:
特にBedrock使用時は有効であるpgvector拡張機能のef_constructionを 256 以上 に設定し、検索精度と速度のバランスを調整。sql CREATE INDEX ON bedrock_kb USING hnsw (embedding vector_cosine_ops) WITH (ef_construction=256, m=16); - 全体の並列ワーカー数上限:
max_worker_processesはmax_parallel_workers_per_gatherの増加に合わせ、8→16に拡大56。 - 不要なインデックスの削除:
使用されていないインデックスは、データの更新(INSERT, UPDATE, DELETE)時にオーバーヘッドとなるため、定期的に確認し削除することが推奨されます。 - 適切なインデックスの作成:
explainで実行計画を分析し、シーケンシャルスキャン(全件スキャン)が発生している箇所や、非効率なインデックスが使用されている箇所を特定し、適切なインデックスを追加します。 - 非シーケンシャルアクセスのコスト推定
:random_page_costはデフォルト値4.0はHDD向けで、AuroraのSSDベースストレージでは高すぎる。1.0→2.0に引き下げ。プランナがインデックススキャンを積極採用。
ランダムアクセスが多いクエリで20~50%の速度改善。
3. I/O と一時ファイルの最適化
log_temp_files:
一時ファイルの発生を監視するため 0(全ログ記録)に設定。work_mem不足によるディスクI/Oを特定し、チューニングの根拠とする。temp_file_limit:
バッチ処理時のディスク溢れを防ぐため、一時ファイルサイズ上限を明示的に設定(例:10GB)。
4. クエリプランマネジメント
- 実行計画の固定:
apg_plan_mgmt拡張機能で安定した計画を強制。RAG の予測可能なレスポンス時間を確保。sql SELECT apg_plan_mgmt.evolve_plan_baselines(sql_hash, plan_hash, 'approve'); pg_hint_planの活用:
オプティマイザの非効率な計画を回避するため、結合順序やインデックス使用をHINTで指示。enable_seqscanの活用:
特定のスキャン方法を制御するパラメータを変更することで、意図したインデックスが使われるように誘導する場合があります。
5. テーブル譜代化防止
- Autovacuumの管理:
テーブルの肥大化を防ぎ、パフォーマンスを維持するためにautovacuum関連のパラメータを監視・調整することがベストプラクティスとされています。
6. 自動チューニング機能の活用
✅ RDS Recommendations
- 機能: CloudWatchメトリクスを分析し、パラメータ不適切さを自動検出。
- 例:
work_mem過小、マルチAZ未設定などの警告と修正案を提示。 - 活用方法: AWSコンソール > RDS > Recommendations で適用 or スケジュール。
Bedrock 固有の最適化事項
- ベクトル処理の効率化:
- ベクトル次元数に合わせた
vector(n)型の定義(例:Titan v2 はvector(1024))。 custom_metadata列への GIN インデックス追加で、メタデータフィルタリングを高速化。
- ベクトル次元数に合わせた
- 接続プーリングの設定:
- PgBouncer や RDS Proxy を導入し、Bedrock Agent からの接続集中を分散。
- メンテナンス時間帯の調整:
- オートバキューム(
autovacuum)の負荷ピークを Bedrock の利用低時間帯にスケジュール。
- オートバキューム(
- 検索タイプ:
「セマンティック検索」と「ハイブリッド検索」のどちらを選ぶかで、検索結果の質と速度が変わります。 ハイブリッド検索は、ベクトル検索とキーワード検索を組み合わせて網羅性を高めます。 - 取得結果の最大数:
一度に取得するチャンク(検索結果)の数を調整できます。 返す結果の数を増減させることで、回答生成の精度と速度のバランスを取ります。 - プロンプトテンプレートのカスタマイズ:
RetrieveAndGenerateAPIを使用する場合、プロンプトテンプレートを工夫することで、より望ましい回答を生成させることができます。
ナレッジベースの推論パラメータの調整
- ナレッジベースの推論パラメータの調整BedrockのコンソールやAPIを通じて、ナレッジベースが回答を生成する際の基盤モデル(FM)の動作を制御できます。これにより、応答の品質をチューニングすることが可能です。
- 温度 (Temperature): 値を高くすると応答の多様性や創造性が増し、低くするとより決定的で一般的な応答になります。
- トップP (Top P): モデルが考慮する単語の選択肢を制限し、値を小さくすると、より一般的な応答を生成しやすくなります。
- 最大トークン数 (Max Tokens): 応答の長さを制御します。
- 停止シーケンス (Stop Sequences): 特定の文字列が出現した時点でモデルが応答の生成を停止するように設定できます。
- データソースと取り込み方法の最適化ナレッジベースの検索精度は、元となるデータの品質と処理方法に大きく依存します。
- チャンキング戦略の選択: ドキュメントをどのようなサイズや区切り方(チャンク)でベクトル化するかは、検索結果の精度に直接影響します。固定サイズ、区切り文字指定、あるいはBedrockが推奨するデフォルト設定などから、データの内容に最も適した戦略を選択します。
- データ品質の向上: ナレッジベースに取り込むドキュメントの質(情報の正確さ、ノイズの少なさ)を高めることが重要です。
- 検索タイプの選択ナレッジベースの設定では、検索方法を選択できます。
- セマンティック検索: クエリの意味を解釈して関連性の高い情報を検索します。
- ハイブリッド検索: セマンティック検索とキーワード検索を組み合わせて、より網羅的な検索を目指します。
クエリとインデックスの最適化
パラメータチューニング以上に効果的なのが、クエリ自体の最適化です。
- インデックス戦略:
ベクトル検索(pgvector)のパフォーマンスはインデックスに大きく依存します。データ量やクエリの特性に応じて適切なインデックス(例: HNSW, IVFFlat)を作成・維持することが不可欠です。 - 複合インデックスと部分インデックス:
複数のカラムを組み合わせたクエリや、特定の条件でフィルタリングするクエリが多い場合、複合インデックスや部分インデックスが有効です。 - クエリの書き換え:
WHERE句で関数を使用するとインデックスが使われなくなることがあるため、クエリを書き換えることでパフォーマンスが向上する場合があります。
チューニング効果の検証方法
- モニタリング指標:
BufferCacheHitRatio: 95% 以上を目標(メモリ効率の指標)。VolumeReadIOPS: 低値安定が理想(ストレージI/Oの負荷指標)。
- 実行計画の分析:
EXPLAIN (ANALYZE, BUFFERS) SELECT * FROM bedrock_kb ORDER BY embedding <=> '[0.1, 0.2, ...]' LIMIT 10;BUFFERSオプションでキャッシュヒット率を確認。
- Aurora の待機イベント分析:
Client:ClientReadやIO:XactSyncの待機時間増加は、ネットワーク/ディスクボトルネックを示唆。
まとめ:ベストプラクティス
- 有効性の高い順での実施:
メモリ設定 → 並列処理 → インデックス最適化 → プラン固定 の順でチューニング。 - 変更時の注意点:
本番適用前には必ず テスト環境で検証。パラメータ変更は カスタムパラメータグループ 経由で段階的ロールアウト。 - Bedrock 連携時の特別対応:
ベクトルテーブルのスキーマ設計時はid/chunks/embedding/metadata列を厳守し、HNSW インデックスを必須化。
✅ チューニングによる 期待効果: RAG のレイテンシ 30~50% 削減、バッチ処理時間 最大70% 短縮(実績例)。
❌ 避けるべき過剰設定:work_memの極端な増加(メモリ枯渇リスク)、max_connectionsの無制限増加(接続競合の悪化)。
パラメータチューニングは「計測 → 仮説 → 変更 → 検証」のサイクルが不可欠です。Aurora の Performance Insights や CloudWatch メトリクスを活用し、データドリブンな改善を進めましょう。

コメント