







Bedrockで正確な情報の出力が必要な場合、基本的にはRAGを選択するのが正しいアプローチです。ただし、タスクの性質によってはAgentが最適となるケースもあります。
結論から言うと、両者の選択は「情報の出所とタスクの複雑さ」によって決まります。
基本原則
- RAG (検索拡張生成): 信頼できる特定の文書群(ナレッジベース)の中から、関連性の高い情報を探し出し、その情報だけを基に回答を生成する技術です。目的は「正確な情報検索と要約」です。
- Agent (エージェント): ユーザーの指示を理解し、自律的に複数のツール(APIやナレッジベース)を使い分け、タスクを遂行する仕組みです。目的は「動的なタスクの自動実行」です。
詳細な比較と判断基準
| 項目 | RAG (検索拡張生成) | Agent (エージェント) |
| 主目的 | 正確な情報検索と回答生成 | タスクの自動実行 |
| 情報の源泉 | 限定されたナレッジベース<br>(S3にある社内規定、製品マニュアル、PDFなど) | 複数のツール<br>(ナレッジベース、社内DBを叩くAPI、外部の天気API、カレンダー予約APIなど) |
| “正確性”の定義 | **「提供された情報源に回答を忠実に根付かせる(グラウンディング)」**こと。ハルシネーション(幻覚)を徹底的に抑制します。 | **「タスクを正しく完了させる」**こと。ツールの選択、APIコールの内容、最終的な応答の組み立てなど、複数のステップの正確性が求められます。 |
| 仕組み | 1. 検索 (Retrieve)<br>2. 回答生成 (Generate) | 1. 思考 (Reason)<br>2. 計画 (Plan)<br>3. ツール実行 (Act)<br>4. 観察 (Observe)<br>(これを繰り返す) |
| 選択すべきケース | 「このマニュアルに書いてあることだけを正確に教えて」<br>・社内規定に関するQAボット<br>・製品マニュアルに基づくカスタマーサポート<br>・法律文書や論文の内容検索 | 「A製品の在庫をDBで確認して、在庫があればBさんにメールで通知して」<br>・複数システムをまたがる業務の自動化<br>・注文状況の確認と顧客への返信<br>・複数の情報源(天気、交通情報、社内ナレッジ)を組み合わせて意思決定を支援 |
| 複雑さとコスト | 比較的シンプルで、コストも抑えやすい。 | 複雑性が高く、思考とツール実行のループでLLMの呼び出し回数が増えるため、コストは高くなる傾向がある。 |
✅ RAG(Retrieval-Augmented Generation)を選ぶべきケース
| 条件 | 理由 | 具体例 |
|---|---|---|
| 情報が非構造化ドキュメントに存在 | ベクトル検索が文脈抽出に優れる | マニュアル/議事録/技術文書 |
| 情報ソースが頻繁に更新される | ベクトルDBのリアルタイム同期が可能 | 株価/ニュース/在庫情報 |
| 回答に出典提示が必要 | ソースドキュメントを自動引用 | 医療/法務ドキュメント |
| アドホックな質問が多い | 事前定義不要な柔軟性 | 研究支援/顧客問合せ |
✅ Agentを選ぶべきケース
| 条件 | 理由 | 具体例 |
|---|---|---|
| 情報が構造化データベースに存在 | SQL/APIで正確なデータ取得 | 在庫数/顧客情報 |
| ビジネスロジックの適用が必要 | ツール連携で決定的な処理 | 注文処理/計算業務 |
| アクションの連鎖実行が必要 | ツールチェーンで複数操作 | 「データ取得→分析→メール送信」 |
| 厳密な入力検証が必要 | OpenAPIスキーマでバリデーション | 数値入力フォーム |
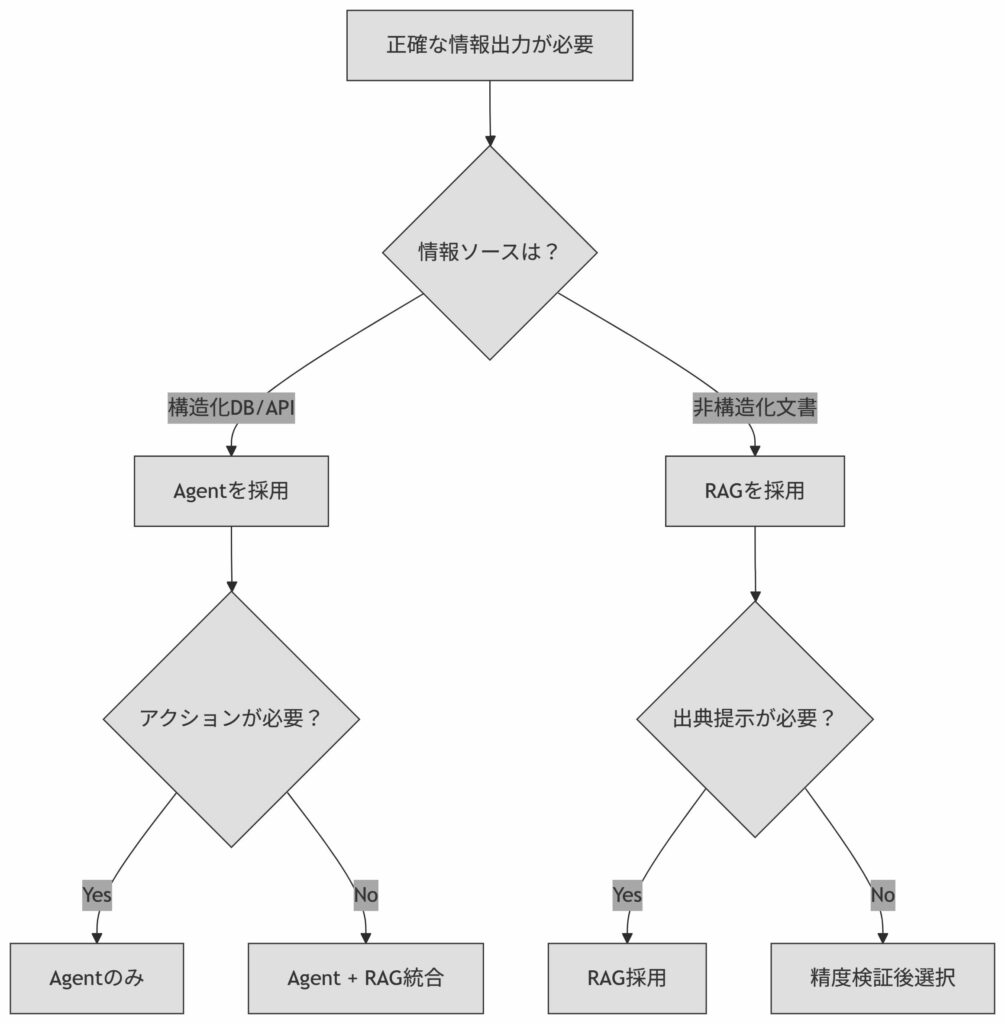
どちらを選ぶべきか?判断フロー
以下の質問に沿って判断するのが最も簡単です。
質問1: 必要な情報は、事前に準備した特定の文書(PDF, Word, etc.)の中にすべて含まれていますか?
- はい → RAG を選択してください。
- これが最も直接的で、コスト効率が良く、情報の正確性をコントロールしやすい方法です。外部の余計な情報に影響されず、文書内の事実に基づいた回答を生成します。
- いいえ → 質問2 に進んでください。
質問2: タスクを完了するために、外部のデータベースへの問い合わせや、別のサービス(メール送信、カレンダー登録など)のAPIを呼び出す必要がありますか?
- はい → Agent を選択してください。
- Agentに「ツール」としてナレッジベース(RAG機能)と、APIを呼び出すためのAction Groupの両方を設定します。これにより、Agentは「まずマニュアルで調べて、次にDBの在庫を確認する」といった複合的なタスクを実行できるようになります。
- いいえ → もう一度、タスクの要件を見直してください。もし単純な質疑応答であれば、RAGで対応できる可能性が高いです。
最適選択の判断フロー
推奨アプローチ:
- 基本方針:
- 数値/状態情報 → Agent
- 解釈/説明情報 → RAG
- 必須追加対策:
- RAG使用時:
検索拡張生成ではなく検索結果そのまま提示モードを設定 - Agent使用時:ツール出力を加工せずに表示
- 共通:Bedrockのガードレールで数値/日付フォーマットを強制
- RAG使用時:
- 最終判断:
「絶対的正確さ」が命のケース(例:医療数値)→ Agent
「文脈付き正確さ」が必要なケース(例:法解釈)→ RAG+出典提示
正確性と信頼性を最大化するには、ハイブリッドアプローチに加え、ヒューマンループ(不確実な場合の人間介入)を組み込むことが最も堅牢なソリューションです。
ハイブリッドアプローチによる最適解
最高の正確性を実現するには両者の併用が効果的です

実装ステップ:
- 質問ルーティング:
def route_question(question):
if is_factual(question): # 数値/日付/IDを含む
return "agent"
return "rag" # 概念/説明系- Agent処理(例:DB照会):
-- Agentが実行するSQL
SELECT stock_qty FROM inventory WHERE product_id = {input_id}- RAG処理(例:マニュアル参照):
# ベクトル検索クエリ
results = vector_db.similarity_search("安全設定手順", filter={"doc_type":"manual"})- 回答統合:
final_answer = f"""
Agentデータ: 在庫数 {db_result['qty']}個
RAG参照: {rag_results[0].metadata['source']}より
{rag_results[0].content}
"""- ガードレールによる検証:
if not validate_numeric(db_result['qty']):
raise AccuracyError("数値検証失敗")まとめ
- 正確な「情報」の出力が最優先で、その情報源が特定の文書群であるならば、迷わず RAG を選択してください。これが基本です。
- 正確な「タスクの実行」が必要で、情報検索に加えてAPI連携など複数のステップが必要な場合は、Agent を選択します。
重要なのは、AgentはRAGの機能を取り込むことができるという点です。Agentのツールの一つとしてナレッジベースを設定すれば、Agentは「この質問はナレッジベースで調べるべきだ」と自律的に判断し、RAGと同様の動きをします。
したがって、まずはRAGで構築を始め、機能要件としてAPI連携などが必要になった段階でAgentへの移行を検討するのが、最も堅実な開発アプローチと言えます。


コメント