 ツール
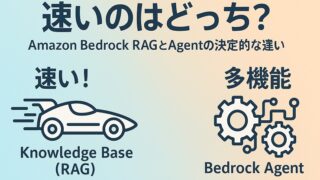
ツール [AWS]レスポンス速度に差が出る理由!BedrockRAGとAgentの決定的な違い
Amazon Bedrockでテーブルスキーマ情報を管理する際、Knowledge Base(RAG) と Agent では、レスポンス速度と機能性に明確な違いがあります。結論から言うと、レスポンス速度はKnowledge Base(RAG...
ツール  ツール
ツール  ツール ツール ツール ツール ツール ツール ツール
ツール ツール ツール ツール ツール ツール ツール  ツール
ツール